No, the title is sarcastic. I just love how I can write a ridiculously bombatic title full of buzz words and still be technically correct, when all I really mean is “making OpalBot more cloud-ish”. I don’t know, it’s funny to me.
A while ago I had this idea of converting OpalBot from a traditional Discord.js application into a cloud-oriented micro-services cluster. Other than sounding more impressive than it really is, this kind of a project would be a great way to learn more about cloud technologies and creating modern applications, which is clearly where the software engineering world is headed for years to come - and a train that I somehow missed by a large margin. Given how OpalBot is a rather small project, has a whole bunch of cloud-like concepts implemented already (such as how SBridge works), and is already partially in the cloud (she’s hosted on a GCP VM and her data is stored in Firestore), I figured this would be a good starting point.
Outside of learning, I also think OpalBot can benefit from such an architecture, especially if I ever end up releasing her as a public bot and having her deal with higher loads. Replacing all the monolithic bulk with decoupled micro-services would mean better routing of tasks and scaling capabilities, as well as making maintenance and operation easier. For example: in order to update almost anything in OpalBot’s code base currently (except for commands or a few custom hot-loaded elements), a reboot is required. This is all fine and dandy when she’s dealing with just one server – but what would happen when it’s 100 servers? 1,000 servers? Even 10,000 servers? A reboot would be extremely costly and lengthy. There are also the limitations placed by Discord itself: for example, an application is only allowed to initiate connections to the events gateway a certain amount of times a day – 1,000 at the time of writing – as well as a delay between every initiation. For bots with many shards, this means only starting up could take well over an hour! Not great, to say the least.
Now, let me get this out of the way already: I am no expert in cloud engineering. A lot of what I’m going to talk about here is based on research I’ve done and some basic understanding of cloud applications; however, do take everything from here onward with a grain of salt. As with most things I do, I learn best as I go, and it’s not unlikely that some of my initial assumptions would be… off.
The Current State
Currently, all of OpalBot’s code and logic is contained within a single Node.js app, separated into what I call modules (not to be confused with actual node modules) and managed with a simple module management system that is controlled through bot commands.
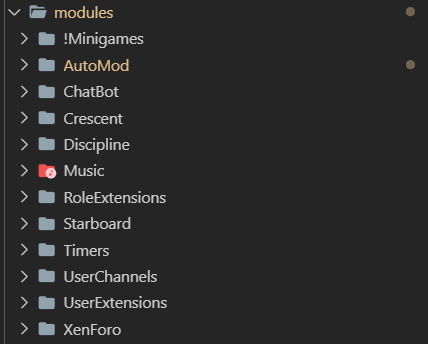
The modules that make up OpalBot. The one prefixed with an exclamation mark is disabled, because I never actually finished it.
The idea is that each of these modules is responsible for a specific set of tasks. For example: the Starboard module handles the Hall of Fame and Hall of Shame – bot managed channels where the messages voted as best/worst in the server are posted automatically for showcasing; and the XenForo module handles things like SBridge and DiscordLink. As per this design, the modules are decoupled – I could take any of them out without affecting the others (as long as they’re not dependent on each other, but that’s a whole different topic).
There is an even more important aspect to modules, though: they are guild-specific. This is what enables OpalBot’s multi-guild functionality. After Discord.js retrieves and loads all the guild objects, OpalBot then creates an instance of each module for each guild. In other words: every guild object has its own instances of XenForo, Starboard, ChatBot, etc. This allows every guild to operate on its own and hold only the data that belongs it. Events from the gateway are then routed to the correct guild from the main Events component (more on this later).
Then there are the commands. OpalBot’s commands are powered by Commando, the official command framework for Discord.js. I switched to Commando during the full v2 rewrite after v1 used an okay-but-could-be-better custom commands system, which took too much time and effort to fix and expand – all while Commando already did it all and then some. On my defense, Commando didn’t exist when I first wrote OpalBot, so I didn’t really have much of a choice!
Finally, there are the core components. These are the critical pieces of code that make OpalBot work, and are not tied to a certain guild. For example: the Database component which interacts with Firestore to load and save data; or the Log module which handles logging to various outputs.
Above all these is the events manager. This is where events fired by the gateway are checked and routed to the correct guild and module. There is a single callback for every event that OpalBot needs, and after some basic processing and sanity checks the data is dispatched to the relevant place.
To sum it up, here is a general diagram of what the architecture of OpalBot roughly looks like:
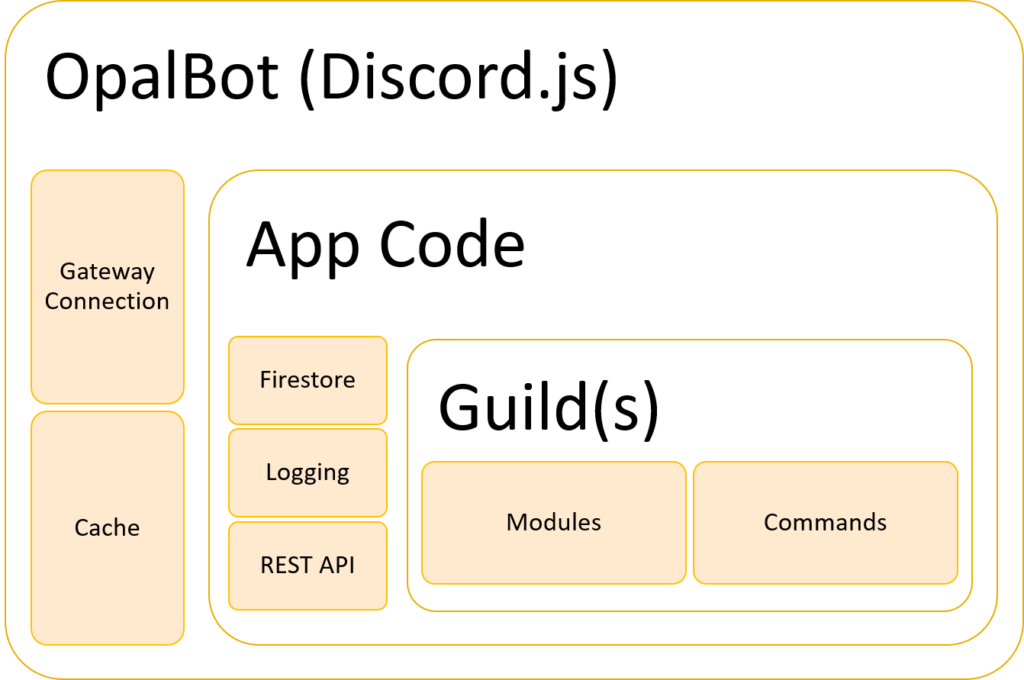
The OpalBot monolith in all of its monolithic glory.
To the Cloud!
How would a cloud setup for OpalBot look, then? First, let’s figure out the key aspects:
- Each of the main components will become its own micro-service. The gateway connection, the cache, the data store, etc. This means they all have to be completely decoupled from each other.
- Data will be transported between the components using some sort of a transportation layer, which is just a fancy way of saying “something that feeds data from one place to another”.
- This decoupling also means that services will be able to access their data directly instead of going all the way through their chain like in the monolith architecture.
With this in mind, a diagram of our micro-services architecture would look something like this:
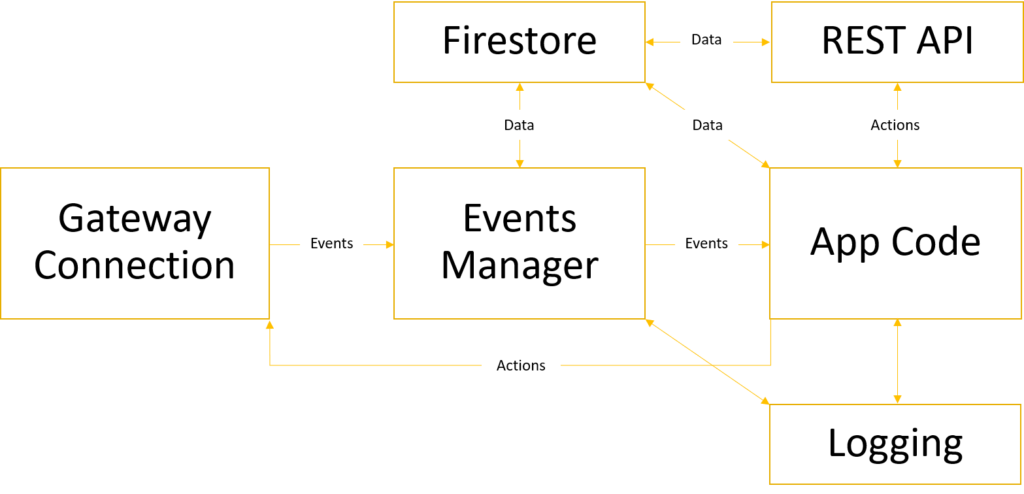
Please excuse my crappy diagram design – PowerPoint is not as great of a tool as I remembered it…
As you can see, all the components are now standalone services, with lots of arrows connecting between them. Actions that initiate those services originate from one of two sources: the Discord gateway, or OpalBot’s REST API. From here, the data begins to flow until whatever it needs to do is done. Some of these events will generate a response; others won’t. One important thing to note is that components like Firestore, the REST API and the logging now live on their own and can talk to each other directly, leaving the actual app to only deal with what it really needs to deal with.
Buckle Up
And that’s the gist of it. There are, of course, a lot of finer details to dive into – but staying loyal to my (messy) work flow, we will discover these as we go and tackle them accordingly. Where’s the fun in all this tinkering, otherwise? 😉
See you at part two.